
In my previous blog “What load can Raspberry Pi handle?“, I tested a configuration where a D2000 system was installed on a Raspberry Pi. Its communication process (D2000 KOM) served both as a Modbus TCP Server and a Modbus TCP Client. I demonstrated that a Raspberry Pi was able to send/receive values of 100 measured points (one change of every tag per second) and store them in a local PostgreSQL database. Then I created a „fast“ configuration using only 10 measured points, which were, however, polled „as fast as possible“. This resulted in 1290 - 1390 values per second (the sampling time of individual values of each measured point being under 10 ms), which were again stored in the PostgreSQL database.
When I published a link to my original RPI blog, in a Reddit discussion I received this substantial objection:
Your demo ignores the primary bottleneck: getting the data over wire
Actually, there was another objection about used communication protocols, but as I don’t have a Simatic S-7 or AB PLC to play with, I will ignore this one for now. So let’s try a modified setup: let’s move the PostgreSQL database from RPI to a different computer. Thus, network latency will certainly influence the overall performance, as every insert into the PostgreSQL database must travel through the network. And let’s measure how much the performance will deteriorate. Or ... will it?
The setup
Ok, so I created a database on a Windows Server (a 10-year old virtual Windows 2008 with 4 GB RAM and 2 vCPU), where a good old 32-bit PostgreSQL 9.6 is running. So we are virtualized and we are on Windows. As you might have noticed, it’s easier for me to reuse old stuff than create brand-new setups.
I also modified pg_hba.conf, so that RPI (IP address 172.16.0.184) could get to this database (see the last line):
And I modified odbc.ini on RPI to connect to this remote PostgreSQL (IP address 172.16.10.50):
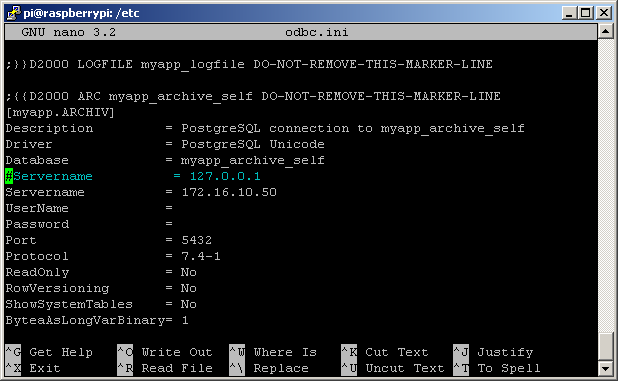
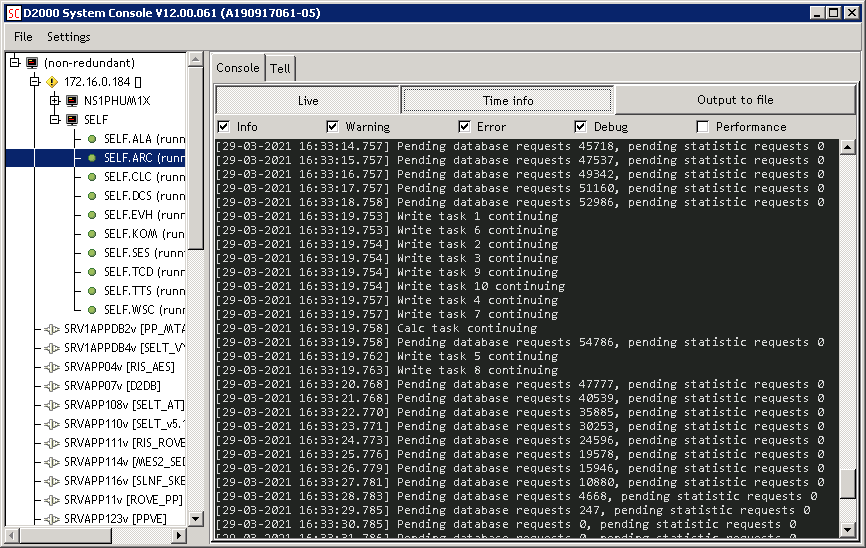
Just to be sure, I connected to RPI and checked the D2000 Archiv configuration by a „SHOW_INFO“ command. Two things can be seen on the following screenshot:
- As the PostgreSQL archive database is on Windows, there is a red warning „GetDiskFreeSpace: Invalid path: D:\PostgreSQL\9.0\D2000“. It means that the path where the archive database is located (which is obviously a Windows path on a Windows server) cannot be queried for available free space (so that „database disk is almost full“ warnings cannot be issued). Never mind for now :-)
- The information about PostgreSQL database is „dba@myapp_archive_self (OID=765031) on 172.16.10.50/32:5432 [PostgreSQL 9.6.9, compiled by Visual C++ build 1800, 32-bit]“. So we are connected to a remote server (172.16.10.50) running a 32-bit version of PostgreSQL 9.6.
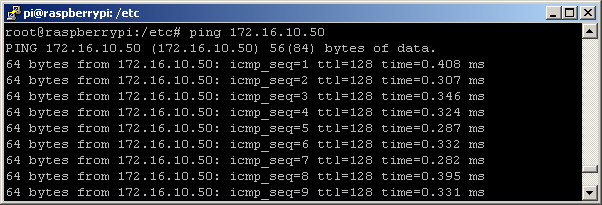
By the way, the RPI is connected to a 100 MBit switch in my office. There are at least 2 more switches on the way to a Windows Server. So a “ping” utility is reporting around 0.3 ms latency.
Now, let’s try to start out basic configuration.
The testing – slow reading
Starting reading of 100 measured points once a second:
Database is empty (size 11 MB), PerformedDatabaseRequest=100 (per second), RPI can keep up ok.

Just to be sure that we are writing to another server:

There are 2 connections for writing, one for reading (I didn’t change this default), one for periodic deleting of old data, and the last one for writing configuration changes.
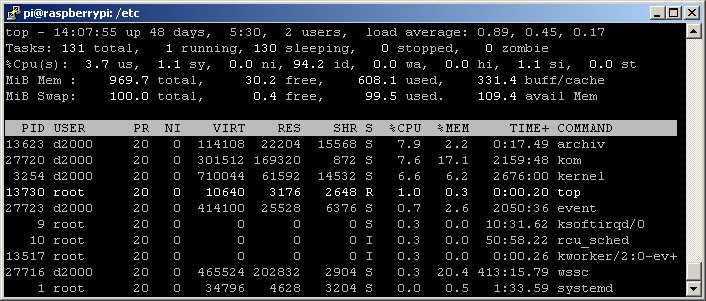
And let’s see RPI load: archiv, kom, kernel, event. Postgres is nowhere to be seen (it is still used by kernel as a configuration and logging database, however, it does pretty much nothing right now).
The testing – fast reading
So, this was rather boringly uninteresting. Let’s stop the slow communication and start a fast one!
Now the problems start to appear. After a few minutes, I see a growing number of the “PendingDbRequest” counter, meaning the network latency (or a Windows Server) prevents us from writing fast enough and some values are waiting in D2000 Archive’s memory queues on an RPI.

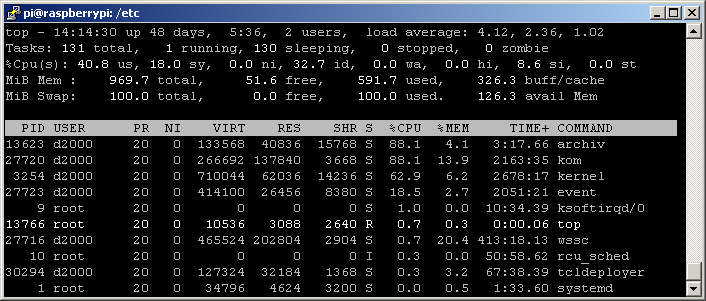
What’s interesting – comparing the numbers with a “PostgreSQL on RPI” scenario from the original blog, the number of inserted values actually increased (from around 1290 - 1390 to 1700 - 1800). This can be explained – more CPU time could be dedicated to running communication when the PostgreSQL archive database was moved away from the RPI.
And this is what the CPU load looks like:
Do we give up now, defeated by network latency? No way. The D2000 Archiv has a number of performance optimizations up its sleeve! One of them was developed to handle the load of large systems, but it can be utilized to suppress the influence of network latency. The magic trick is using multiple parallel write tasks.
We will increase the number of parallel write tasks from 2 to ... let’s say 10 (so that every archived point can have its own task). This way, multiple parallel write connections are used to insert data into the PostgreSQL database. So, we change WriteThreadsCount from 2 to 10 (implementing this feature took a few weeks ... some 10 years ago ... but it was worth the effort).

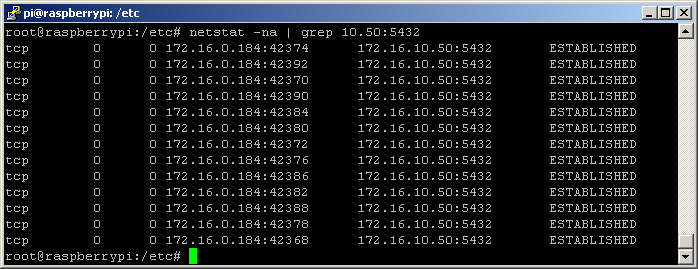
After restarting the D2000 Archiv process, the number of connections to the PostgreSQL server has increased.
Now, the “PendingDbRequest” counter is steadily on zero. Performed requests are between 1700 and 1800, sometimes they go even higher:

And how about the “FREEZE 30 30” test to find out maximum throughput of this scenario?
As you can see, more than 54000 values (accumulated in 30 seconds, that’s 1800 values/sec) were processed in 10 seconds. That’s 5400 values/sec. Actually, in these 10 seconds, further 18000 values came from communication and have been processed. This gives us 5400+1800 = 7200 values/sec for an “RPI + virtualized Widows Server” team :-). Just to remind you, the peak performance in an “all-on-RPI” scenario described in the original blog was around 2500 values per second.
The testing – a remote Modbus server
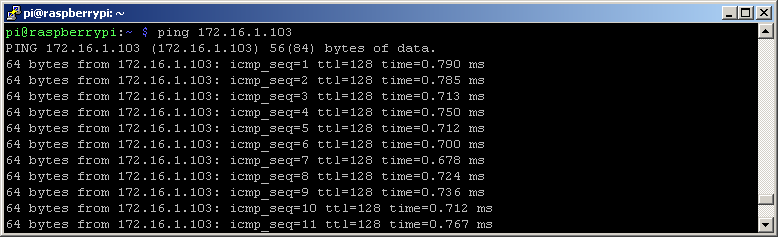
When I wrote previous few paragraphs yesterday, I started to be curious, how badly the Modbus TCP communication would be influenced by the network latency. So this morning I exported the Modbus Server line, station and ten “fast” Modbus server output I/O tags, together with a user variable which controls the I/O tags. And then I imported them to an application running on old HP workstation (production date: 2008, Windows Vista, 2-core CPU). The ping times are even worse than for a database server, though the two computers are on the same switch in my office:
Let’s verify that the communication works – I used the default Modbus TCP port 502:

And let’s look at how many values are being written to the archive database:

Wow. I expected a certain drop in numbers. But instead, we’ve gone from 1700 – 1800 to around 2800-2900 values per second. I didn’t actually want to believe this, so I looked directly at the statistics of B.ModbusCliFast line. The column „Changes“ contains number of changed values on this station in the last 10 seconds – it’s 28402 on the next screenshot.

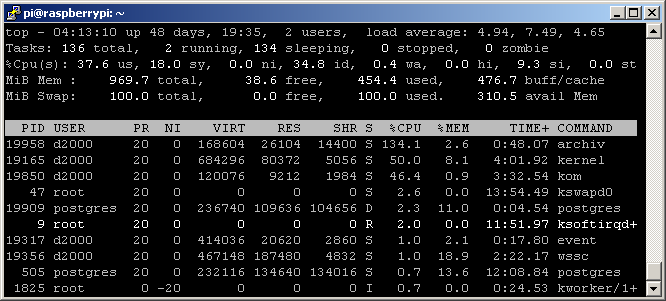
How about the CPU load on RPI? As you can see, the D2000 Archiv process consumes the most of CPU. D2000 Kom’s load is approximately half of what it used to be before offloading the Modbus Server to another computer.
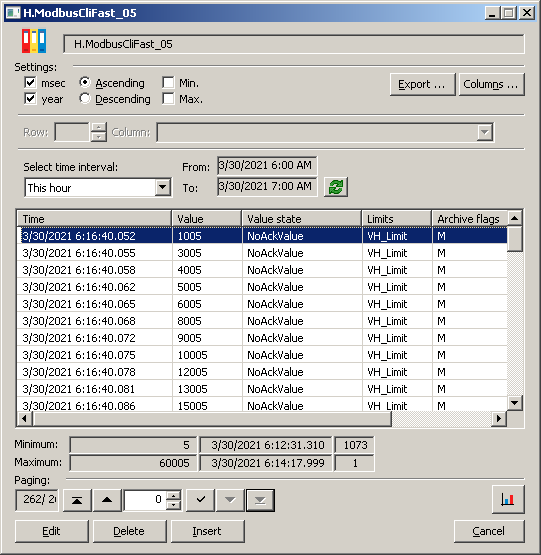
Let’s look at the data in the archive database. The timestamps mostly differ by 5 or less milliseconds.
Conclusion
Let me repeat what I wrote in my original blog. Take these results as “illustrative only”. They depend on the hardware (and software) used. However, writing to a Windows-hosted PostgreSQL actually improved the performance results. So did moving the Modbus TCP server to an old Windows workstation. So it seems that the benefits of offloading the RPI are greater than the disadvantages of network latency. On one hand, this confirms the fact that the RPI is far from being super-fast. On the other hand, it proves that the Raspberry Pi is fast enough to be used to collect the data and store it in a remote SQL database.
Ing. Peter Humaj, www.ipesoft.com
