
Today we bring you freshly translated blog post focusing on the topic of predictive maintenance and how to achieve long-term high reliability of SCADA and MES systems. Since it is some time since the original Slovak blog post was written, author updated the content to be even more relevant.
“Do the predictive maintenance? And why - the system works. If it stops, we will deal with it. Predictive maintenance is a waste of time. "
Your customer can also have such an opinion after the deployment and handover of the SCADA or MES system into operation and during the subsequent negotiation of the service contract. Let's try to analyze their objections and show examples of how prophylactics can be automated and performed as effectively as possible.
"And why, the system works." Using this argument, car owners could ignore service inspections, oil changes, brake pad wear checks, and so on. Why - the car works .. They would certainly save, at least for a short time .. to the first breakdown, which according to Murphy's laws would come at the most inopportune time.

Applying the analogy to the world of SCADA/MES systems? Unnecessary failures due to full disks or databases, loss of data due to failed communications that have not been monitored, or complete application failure.
The importance of predictive maintenance is even higher in redundant systems. There, the failure of one component (application server, archive server, a network switch, power supply, or disk in a RAID array) will not affect the functionality of the system – however, that makes its detection and subsequent troubleshooting even more important. Otherwise, the customer can go complaining to Mr. Murphy in a few days or weeks in the event of a failure of the other component that has worked so far. So - why invest in a redundant solution (read: more expensive than standard), if the customer doesn't service it and is not sure they can always rely on it?
"If it stops, we will deal with it." If we start solving the problem only when it occurs (reactive maintenance), it is usually more expensive. The proverb says that a gram of prevention is better than a kilogram of medicine. There is a risk of data loss, unavailability of the service, dissatisfaction of users, or customers. There is the question of the supplier's availability when dealing with the incident (what are his SLAs, will be available on Sunday or at three o'clock at night - and how quickly will he repair the error?). Alternatively, when solving on our own, how quickly, with what quality (and how willingly) will our technicians be able to eliminate the problem? Mr. Murphy would say that incidents are frequent during technical staff holidays and scheduled out-of-premises training ...
"Predictive maintenance is a waste of time." Hm. It may be. Like any activity, if done badly or inefficiently. As far as predictive maintenance concerns SCADA and MES systems, it should be noted that these are systems for automated data collection (Supervisory Control And Data Acquisition). And what other systems should have built-in automation of predictive maintenance activities, if not these?
So a simple recipe for predictive maintenance: invest a one-time effort to automate the most common predictive maintenance activities (collecting diagnostic data about system status, automated ‘maintenance’) and then let technicians solve the problems reported by diagnostics.
Too general and vague? All right, let's try to turn a banknote of theory into small coins of practice from the IPESOFT company. Facts:
- System class: SCADA / MES / EMS / SELT / SKEI / SKVI ...
- Base technology used: D2000.
- Automated predictive maintenance module: since 2010.
- Number of systems with deployment: approx. 90.
- Deployment of the predictive maintenance module: several hours to tens of hours depending on the size of the system.
The prophylactic module provides monitoring of:
- Servers and devices: network availability, uptime.
- Windows, Centos/RedHat, HP-UX, OpenVMS operating systems: memory usage, the number of handles and threads, swap usage, disk usage.
- D2000 processes: uptime, allocated memory, the number of handles, the status of redundant processes.
- Communications: functionality of communication, numbers of new values from communication.
- Archives: free space, number of processed requests per second and requests in queues.
- Databases: free space, number of parallel connections to the database.
- HW server status: checking the status of HP servers (using WBEM / CIM / SNMP) in Windows, Centos/RedHat, VMware, HP-UX, and OpenVMS operating systems.
- Disk array status (MSA2000 G2, P2000 G3, P4300 G2).
- Backups - monitoring the age and size of backups + active execution of backups (configuration and monitoring databases, archive and application databases - SQL Anywhere, Oracle, PostgreSQL, MariaDB platforms, application directories, the Windows registry database, etc.)
- Application-dependent parameters that are specific to individual applications. It can be practically anything that is considered important. Monitoring the status of the Oracle cluster, ‘frozen’ values from communication, the status of application scripts, receiving emails, or the average load of the application server.
How does it work?
- The prophylactic subsystem collects data.
- Archive subsystem stores them (usually for 1 year with optimally set on-change filters).
- Logic evaluates alarm states (e.g. 85% disk full).
- Local administrators have access to prophylactic schemes.
- Systems with contracted prophylactic control regularly send prophylactic data to a prophylactic server in IPESOFT, where they are evaluated by a dedicated application.
- Technicians then analyze and resolve the reported alarm conditions displayed on the dashboard scheme.
Examples of prophylactic scheme screens available to local customer administrators:
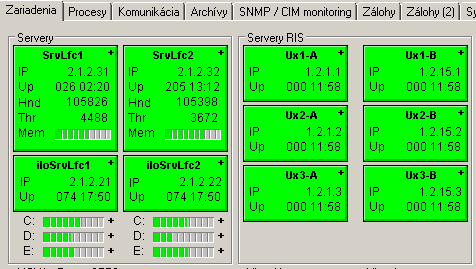
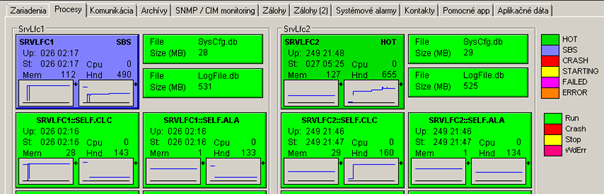
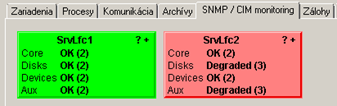
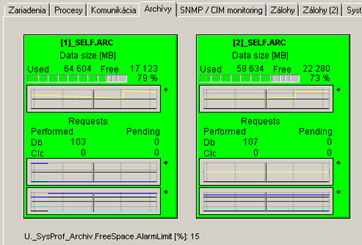

Real benefits of automated predictive maintenance? For customers and for us:
- Significant reduction in the number of service incidents handled by technicians serving 24/7 emergency (and reduction of stress, which affects the satisfaction of technicians :)
- Higher customer satisfaction - many of the problems are solved before the consequences begin to be perceived by users.
- Lower maintenance costs (effective problem solving during normal working hours instead of more expensive emergency solutions).
- Use of archived data for further analysis or planning. E.g. questions such as "Since when and why is our archive filling up at an increasing rate?" or "Did the PLC replacement increase the MES load due to the higher amount of data transferred?" or "How long will it take for the database to fill up completely if we do not increase the capacity of the disk array?"
- Use of archived data for troubleshooting. For example, we have recently proved that a few minutes of communication failure is not the responsibility of any of the communicating parties, but it’s due to the problems in the network infrastructure - thanks to the monitoring of the availability of network devices on the communication route.
And a few more technical curiosities:
- At the beginning of development (2010), the prophylactic module was designed to be deployed on all then supported versions of D2000 (from version 7.2.05 through version 8.x). It is currently deployed on versions 7.2.05 up to the latest 11.0.52.
- The prophylactic server in IPESOFT contains a copy of prophylactic schemes from customer systems. This allows technicians to view detailed customer data, perform basic analysis, and often determine the severity of a problem without having to log in to their systems.
- After modifications of prophylactic schemes at the customer (e.g. due to application expansion) it is enough to perform XML export of changed schemes and their import on a prophylactic server.
- Prophylactic data is transmitted via e-mail without the need for a direct connection between the customer's and IPESOFT's networks. The data is zipped and encrypted using the AES-256 encryption algorithm before it is sent.
- Prophylactic data is sent at least once an hour, but if an event is evaluated as an alarm (e.g. database is full above a specified limit), sending within a minute is activated. This delay is due to the accumulation of subsequent alarms, should they occur - e.g. a network unavailability alarm may be followed by a communication status alarm. The prophylactic server also notifies the operator that the last data was received from the customer more than an hour ago.
What to add at the end? Nearly seven years of experience with automated predictive maintenance convince us that effective prophylactic checks are not a waste of time, but keeps the system functional, available, and in good condition. It contributes to the satisfaction of both users and suppliers. It also provides data for problem analysis, measurement of system parameters, and planning of resources needed in the future (e.g. disk space). We plan to continue to improve, expand, support new hardware, and new versions of operating systems.
Ing. Peter Humaj, www.ipesoft.com
Addendum 2021: it’s been over 3 years since I wrote this blog in Slovak. Now that it is translated to English, I might add a few bullets to the list, as our predictive maintenance Sysprof keeps being used and enhanced.
- We lately implemented support for the monitoring of Dell and Huawei servers.
- We started using Pacemaker/Corosync based PostgreSQL high-availability solutions, therefore we implemented its monitoring.
- Monitoring of Oracle database was enhanced to include monitoring of free space in temporary tablespaces.
