
Learn how to secure your data with redundant PostgreSQL.
Do you use redundancy in your solutions? As far as mission critical applications are concerned, our customers' answer is usually yes. Redundant D2000 application servers, redundant LANs, redundant archives, communication processes and communication routes - depending on the nature of the application, they use some or all of the redundancy types supported by the application server D2000.
But how about external databases accessed by the D2000 DbManager process?
In the past, we used Oracle RAC (Real Application Cluster) in applications that required a redundant database. The current state of technology allows us to deliver powerful solutions based on PostgreSQL databases that implement high availability.
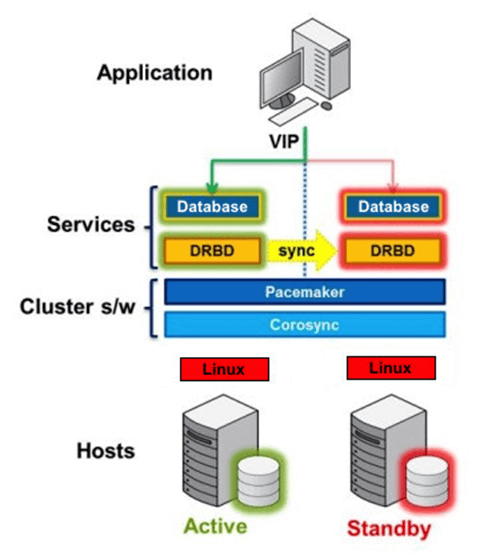
How does it work?
- at the bottom, there are 2 Linux servers (physical or virtualized)
- data replication between servers is provided by DRBD
- above is the Linux clusterware Corosync and a Pacemaker cluster resource manager
- the PostgreSQL database is running on a shared virtual IP address
DRBD (Distributed Replicated Block Device) provides storage of database data on both Linux servers, making it available even when one of the servers fails.
Clusterware handles the start of the PostgreSQL database on the active node. At the same time, it ensures that the necessary resources are available (IP address and DRBD replicated database disk). If an active server fails, the standby server takes over its function. This means that the DRBD on this server becomes primary, the shared virtual IP address is assigned to the server, the shared file system is mounted, and PostgreSQL is started.
Of course, a redundant solution also needs to be monitored - otherwise it may happen that when one of the servers becomes inoperable, the entire high-availability solution works (which is the desired state), but no one knows that something needs to be repaired (which is unwanted). Subsequently, the second server drops out as well – the users will experience this as an unavailability of the database.
It is possible to monitor the individual components of the solution manually (with the appropriate configuration tools) or with various utilities. Since our solutions use their own prophylactic module to support monitoring of individual parts of the solution (from hardware level, through operating systems, databases to application functionality), it was logical to go this way.
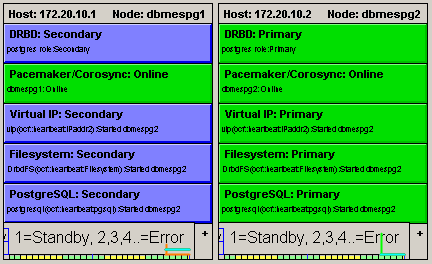
So last week we successfully integrated PostgreSQL cluster monitoring into our prophylactic module, which is deployed on dozens of serviced applications. Individual components of a high-availability solution (DRBD, Pacemaker / Corosync, virtual IP address, shared file system and PostgreSQL database itself) are periodically queried and their status is evaluated.
In the case of detected problems, these are shown in a prophylactic scheme (see figure below). The information is then also sent to the prophylactic server in Ipesoft, where one of our Linux and PostgreSQL specialists can address the problem. Thus, potential problems can be analyzed and resolved without impact on operation.
Conclusion
At present, we are able to offer our customers not only redundancy of D2000 real-time application server itself but also redundancy of external databases. In addition to the Oracle database, we also offer high-availability solutions built on most advanced open-source database PostgreSQL. We can not only configure and manage such solutions, but also continuously monitor and track the status of each component.
