
In the previous article “Archiving in SCADA and MES systems” we described the features of archiving in SCADA/MES systems from the point of view of the user (or the configurator that creates archive objects). This article focuses on the "enterprise" properties of archives. By this, we do not mean a resemblance to the spaceship from the sci-fi series Star Trek, but features that allow it to be used for large-scale enterprise solutions. Not every archive subsystem is suitable for use in applications with thousands of archived values per second, tens of thousands of archive objects, hundreds of gigabytes of archived data, and hundreds of users connected in parallel.
"Enterprise" properties are properties that affect the ability to archive data, read data from the archive, and use server resources (CPU, memory) so that the application is scalable in multiple dimensions (number of archive objects, number of archived values per second, the volume of archived data, number of users) as well as properties affecting the availability of the archive and ensuring the minimization of planned and unplanned outages. The support of diagnostics and measurement of the performance of the archive subsystem is a bonus. So - what can the D2000 real-time application server and D2000 Archive offer in this regard?
Redundancy of archiving and load-balancing
Archiving redundancy has already been described in a separate article "Redundant SCADA/MES systems and D2000". It is possible to configure multiple archive processes (usually on different servers) to archive the same data, each in its own database. Individual archive processes are called instances in the D2000 system. One instance can be active - it implements user requests for access to data. Other instances are passive - they only write. When load-balancing is enabled, there are multiple active instances, and the D2000 Server process controls the routing of reading requests to instances.
If one of the instances is switched off (e.g. due to maintenance) or dropped out, the data is archived and provided by the other instance resp. by other instances.
How to solve the situation after a failure or shutdown of one of the instances? The D2000 Archive implements automatic "patching" of the created hole in the data. It can detect for how long period the data is missing and run a utility that retrieves data from another instance and inserts it into an archive database. As a rule, only primary data are entered and subsequently, after the hole is filled, the D2000 Archive performs a recalculation of the statistical and calculated archives for this period.
If the customer does not have sufficient disk capacity to create a full-fledged redundant archive, a partial solution is also possible - the creation of the so-called short-term archive. This is configured (by a start parameter) to have a limited archiving depth of all objects (e.g. for 1 month or 1 week) and thus it has significantly lower disk space requirements than a standard archive. In the event of a failure of a full-fledged archive, users have at least a few days of data at their disposal - and administrators have several days to make the archive work before the collected data is deleted from the short-term archive.
Support for SQL servers from various manufacturers.
The D2000 Archive uses SQL databases to store data. Multiple servers are supported:
· Microsoft SQL server
· Oracle
· PostgreSQL
· Sybase SQL Anywhere
Microsoft SQL Server and its freely distributable versions MSDE and SQL Express Edition are primarily used by OEM partners to create smaller applications. Sybase SQL Anywhere has proven itself for applications up to approx. 20-40 GB data. The Oracle database has an excellent performance in terms of the number of writes and the number of bytes it needs to store a single archived value. PostgreSQL lags behind Oracle in performance, on the other hand, it is used more and more due to high stability and low demands on memory and administration. In enterprise solutions with large amounts of archived data, only Oracle and PostgreSQL databases are used.

The choice of a specific database and version is also influenced by customers - some require e.g. use of Oracle databases, which they have established as a corporate standard.
Long-term archiving (depositories)
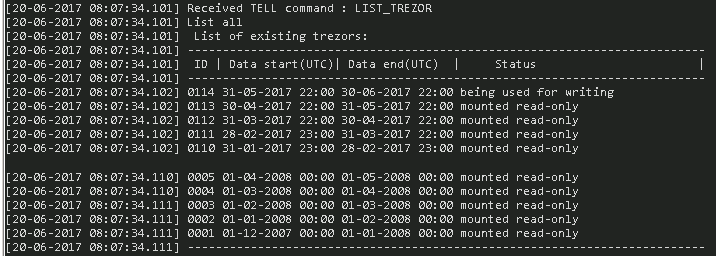
Until now, when configuring archive objects, we have always considered that their historical data is stored only for a configuration-defined period (a month, a year, 5 years ..). Practice required the introduction of "unlimited" archiving, even at a time when disks were small and expensive. How to resolve such a discrepancy? The authors of the D2000 Archive implemented a feature called depository databases or depositories. The archive with active depositories stores data in a standard archive database and in parallel in the so-called depository. Storing in the depository can be enabled or disabled for each archive object. Once created, the depository is being filled for a defined time (usually a month, but it can also be a week or 10 days), and then it is disconnected and a new depository begins to be filled. After it is disconnected, it is possible to copy the depository away, or burn it to a CD-ROM and insert it into a real depository, as was the case with the first customer who required this functionality - hence the name. Old depositories can be reconnected and data can be read.
Depositories were originally supported on Sybase SQL Anywhere (as stand-alone databases), later on Oracle (as tablespaces), and on PostgreSQL (again as stand-alone databases).
At present, thanks to large disks, filled depositories do not have to be disconnected, but remain available for reading. If the depositories are full, the older ones are moved, e.g. to NAS drives (slower but cheaper), so users have the full required depth of data available.
D2000 Archive allows you to run a user-defined command after filling the depository - this is used to back up the depository, e.g. to independent network storage in case of failure of disks with depositories.
Redundant archives often use an asymmetric configuration in which only one archive instance has depositories enabled. D2000 allows you to set up an instance with depositories as a so-called preferred instance - if the instance is available, it will be active and users have long-term data available.
The other three enterprise features relate to the use of multiple cores (parallelization) and a large amount of memory (caching) that current servers have available. Their implementation took place from 2006 to the present.
Parallel reading from the archive
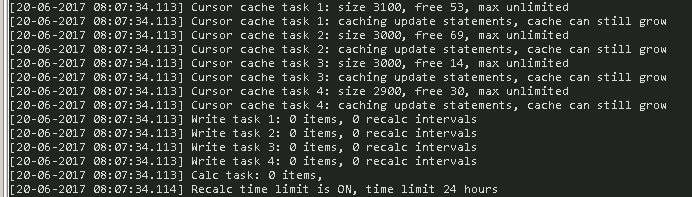
The D2000 Archive permits the configuration of up to 10 read tasks that handle client requests in parallel. If a client requests data for a longer period of time, which can take several minutes to read from the archive and depositories, then other tasks can process requests from other clients in parallel - from their point of view, the archive does not "hang" for a few minutes, but provides data (although maybe slower due to load on SQL server and disks).
Parallel writing to the archive
Write parallelization can significantly increase write throughput on multicore servers. The D2000 Archive supports up to 16 write tasks (if necessary for even more demanding applications, it is enough to recompile it with an increased definition constant). Parallelization of writes was much more complicated than parallelization of reading - this is related to the dependencies among archive objects as well as the "session isolation level" properties of SQL databases. The dependencies among archive objects requires that the calculations of the calculated and statistical archives be performed in an appropriate order (although they are performed by tasks with different workloads). The problem with the "session isolation level" is that neither Oracle nor PostgreSQL allow one connection to a database to see data that another connection has not yet committed. Therefore, it is necessary to implement a small cache shared by all tasks in the archive, which contains uncommitted data and ensures that the calculation has the data of the source archives, even though this data may have been inserted into the database by another task that has not performed commit yet.
In addition to parallel write tasks, it is also possible to configure one "calc" task that performs writes and recalculations of values older than a configurable limit. The purpose of this task is to ensure that the arrival of old values, which can cause significant archive activity, does not overload the write tasks, but that the old values (and subsequent recalculations) are processed more slowly on the auxiliary "calc" task.
You can learn more about the Enterprise features of archiving in SCADA and MES systems in the Part II of our blog.
