
"It's simple: I take a value, throw it in the archive, and it's there. And that is all. Why do you want to write an article about it? ”
Historical data in the SCADA and MES systems are understood as one of the most important assets. That is why we often encounter that the archive subsystem of our customers (abbreviated as an archive) is built as redundant, or in smaller applications the redundancy of archives is approached as one of the first issues during deployment and transition from the pilot phase of the project to mass production.

So what functionality can the SCADA and MES archive provide? In the following description, we will show examples from the D2000 archive subsystem, which is part of the D2000 real-time software technology.
The basic functionality has already been mentioned above - data archiving (whether it is the values of objects from the communication, calculated values, manually entered, or other). Let's call these archive objects primary archives. Primary archiving can be on-change or periodic.
Each archive object has a defined archiving depth - the period for which the values are stored in the archive database. Older values are usually deleted and in this way, the archive database maintains approximately the same size after the initial filling. Some systems have a limited set of archiving depths defined (e.g. daily, weekly, monthly, yearly). D2000 Archive allows you to set arbitrary depth of archiving on each archive object.
What next? The logical requirement is the definition of statistical archives. Users require data on averages, maximums, amounts, and other statistics for archived values. Statistical archives usually have a bigger archiving depth than their source archives (e.g. on-change data from communication changing every second is archived for 1 month and minute averages for 1 year). Unlike the primary archives, statistical archives are always periodic.
Another useful type of archives is calculated archives, which implement any user-defined function over their source archives. E.g. archive object H.X with function (H.A + H.B + H.C) / 3 calculates the arithmetic average of three archives H.A, H.B, and H.C. Like primary archives, calculated archives can be on-change or periodic. The D2000 Archive, therefore, contains a calculation subsystem using the same syntax as the process performing real-time calculations - D2000 Calc.
Statistical and calculated archives do not have to work with primary archives only, but the source for them can be any archive objects - also statistical and calculated. In practice, this can be used to create relatively large archive "trees", which combine statistical and calculated archives and calculate e.g. minute or quarter-hour energy balances of the whole production plant.
When we talk about dependent objects, a good SCADA/MES system should maintain the referential integrity of the objects – to be aware whether the object is being used by another object and, if so, prevent it from being deleted.
So these are all types of archives, right? Well, almost: a special type of primary archives, which have no source object configured, are archives filled from a script. As the name suggests, they are used to store data that is filled with a script (e.g. based on user-entered data or as a result of importing an external file or retrieved from an external SQL database).
In the D2000 archive, scripting functions can also be used for ordinary primary archives. An example of use in practice are primary archives archiving measured points (called I/O tags) from communication, specifically the IEC104 protocol. Since this protocol does not support the reading of historical data (e.g. after a communication breakdown), in a specific application the PLC also saves the data to files on disk, from where it is read by a script and stored in primary archives after recovery from a communication failure.
And speaking of historical data from communication, several devices (dataloggers, electricity meters, OPC HDA servers ..) allow reading historical data. What can we do with them next? We definitely don't want to show old data to users in schemas - but we want to store it in archives! The D2000 Archive offers this functionality too. But what is important - after archiving, it automatically recalculates the values of statistical and calculated archives, which are affected by the arrival of old data of primary archives.
Here is a qualitative difference between the arithmetic performed by the calculation process (D2000 Calc) over the current values of objects and the arithmetic of the D2000 Archive. Arithmetic working with actual values has no way of making corrections to historical data. The arithmetic of D2000 Archive automatically ensures consistency of statistical and calculated archives after the arrival of old values of primary archives as well as after inserting old values from the script (when scripting, it is possible to choose whether dependent archives should be recalculated immediately or manually start recalculation after insertion into multiple archives).
The importance of maintaining the consistency of statistical and calculated archives will be also manifested if the values from the communication already come with time stamps. In this case, some communications may send ‘new’ values, but the timestamp is older than the current time (by a few seconds, minutes, or more). Even in this case, the D2000 Archive will ensure consistency.
If there are a large number of measured points from the communication with a varied scattering of timestamps in the application, there is a risk of overloading the archive due to the fact that it tries to maintain consistency and recalculates statistical and calculated archives e.g. for the last few minutes. In specific applications, the request queue could reach hundreds of thousands or millions of values. What about that? The creators of the D2000 Archive also thought about this. In the configuration of statistical and calculated archives, it is possible to choose the calculation condition. By default, the calculation is done continuously, but it can be configured to be performed on-demand. This means that such an archive will not be calculated continuously, but only as a result of a user command or action from a script, the calculation of one, more (according to the specified mask applied to the names of the archive objects), or all archives for the selected period will be started.
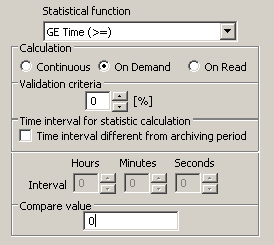
In practice, archives calculated on-demand are used in balance systems. The calculation is initiated automatically from a script e.g. every hour at the 10th minute, when data from the previous hour is assumed to be available.
In the previous picture, the "on-read" calculation option is also visible. What is it? Another interesting feature of the D2000 Archive. It is a ‘virtual’ calculated or statistical archive that does not actually exist in the archive database - so it does not cause disk/CPU loads by writing values. When a user or a script requests data, the data of the source archive object (in the case of a statistical archive) or even several source archive objects (in the case of a calculated archive) are read, the calculation is performed and the data is sent to the demander. In exchange for the saved disk space, you sacrifice the time required to read the source data and calculate it, so such archives are suitable if their use is sporadic. It should also be borne in mind that the availability of data depends on the depth of archiving of source archives (if there are several of them in the calculated archive, then of course the calculation has only the data for the shortest of the archiving depths of source archives).
For primary archives, we have stated that primary archiving can be on-change or periodic. In the case of on-change archiving, it is possible to define what a change is - using a filter.
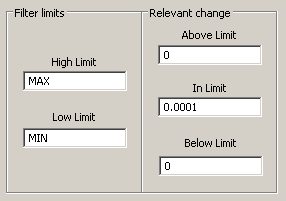
The D2000 Archive allows you to define up to three different filter sizes - within defined limits, below the lower limit and above the upper limit. If the filter is zero, any change in value is archived (even if the value does not change numerically, only the timestamp changes). For a non-zero filter, a new value is archived if its difference from the last archived one is greater than or equal to the size of the filter. This can save disk space and reduce CPU and disk load by filtering out minor changes.
In the second part of this blog, you will learn about making your work easier with structured archives, and about archiving future data :).
