
The PostgreSQL database platform is becoming more and more popular also with our customers. This is evidenced not only by new projects using PostgreSQL as an archive or a MES database but also by migrations during upgrades of existing applications.
For archive databases, the arcsynchro utility is used to migrate the data. It connects to the source and destination archive databases via ODBC and copies the data based on the specified parameters (time interval, mask or range of object IDs, etc.).
In practice, data migration takes days to weeks. A tougher nut to crack is depository databases - due to the volume of data. Understandably, hundreds of gigabytes of data collected over the years may take a long time to copy.
The conversion of depository databases at a specific customer (from Oracle to PostgreSQL) took several months. Another, even bigger conversion is currently underway, so we looked at how to speed up this data copying.
Parameterized queries and batch data loading
The ODBC interface offers the possibility to parameterize an SQL query (e.g. INSERT) - instead of specific values, parameters will be used - e.g. INSERT INTO Data (time, value) VALUES (?,?) - and then the SQL query is called many times repeatedly, with the parameters being filled with different values. Another advantage of parameterized queries is that some activities are performed only once (parsing the query, evaluating user access to the table, creating an execution plan by the optimizer, etc.).
Parameterized SQL queries are commonly used in D2000 - in dbmanager, archive, and in arcsynchro utility. ODBC, however, allows you to fill the entire array of parameters and perform e.g. 1000 queries in a single call – i.e. insert 1000 lines at once – so-called multirow inserts. Which often speeds up data entry even further.
Therefore, data storage in PostgreSQL depository databases has recently been implemented in the arcsynchro utility in this way. In anticipation of the acceleration, we ran the tests and the result was disappointing - the acceleration did not take place.
Enabling logging in the PostgreSQL ODBC driver and later viewing the ODBC source code revealed the cause - internally the ODBC driver inserts rows into the PostgreSQL database one by one.
Drivers by PostgreSQL, EnterpriseDB, and by an independent manufacturer of ODBC drivers for PostgreSQL - Devart - were tested. Multirow inserts were not faster in any of the drivers - although developers wrote on the Devart forum that they would look into it and hope to be able to speed up batch data loading.
Using text files
What now? Instead of waiting, we looked at alternative ways. For example, there is a possibility to insert data from a text or csv file (so-called COPY TABLE). The problem is that if duplicate data already exists in the table, COPY TABLE will fail - unlike the INSERT statement, which in PostgreSQL since version 9.5 supports the ON CONFLICT UPDATE clause and thus allows the data to be overwritten (so-called UPSERT).
However, while searching, we came across a forum describing the operation of the file_fdw extension. This extension (which is part of the standard PostgreSQL installation) allows you to define a text or database file as an external table.
The example will probably illustrate this best:
First we will create the appropriate extension in the database:
CREATE EXTENSION file_fdw;
Then we create a ‘remote server ’, which is handled by the extension:
CREATE SERVER import_t FOREIGN DATA WRAPPER file_fdw;
Finally, we define a remote table belonging to a remote server:
CREATE FOREIGN TABLE mytbl (id INTEGER, cas TIMESTAMP, value DOUBLE PRECISION) SERVER import_t OPTIONS ( filename 'D:\data.txt', format 'text' );
When defining a remote table, we specify where the file is located and what its format is (text, csv, binary). Next, we can use the SQL INSERT statement to insert data from the mytbl table into a standard table (e.g. located in a depository database) using the UPSERT syntax:
INSERT INTO data(id, cas, value) SELECT * FROM mytbl ON CONFLICT (id, cas) DO UPDATE SET value=EXCLUDED.value;
Subsequently, we can delete the text file, or create it again with other data and repeat the insertion (the extension does not prevent this if the SQL statement has already ended).
Implementation in arcsynchro
The support for described functionality was implemented in the arcsynchro utility. If PostgreSQL depositories are being filled, a new start parameter /FM <path> can be used.
FM stands for ‘File Mode’ and <path> is the name of the directory in which the text files will be created.
Attention - this directory must be accessible for PostgreSQL to read (by default PostgreSQL runs on Windows under the Network Service user). This also means that arcsynchro must be run on a computer with target depositories (which is not a problem in practice). In addition, using UPSERT means that the feature will only work in PostgreSQL 9.5 and higher (which is also not a problem in practice, as we usually install the latest versions of PostgreSQL and can upgrade older ones).
Arcsynchro inserts into the text file at most as many values as specified by the /CM parameter (commit), and then performs the insert from the remote table. In practice, the default value of the /CM parameter (1000) for ‘File Mode’ is small and therefore we used a significantly larger - /CM 500000.
What are the real results?
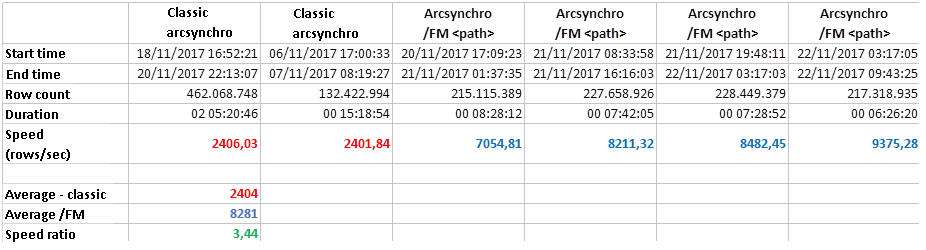
The classically running arcsynchro is able to insert data into depositories at an average speed of around 2400 values per second. Improved arcsynchro using the parameter /FM averages almost 8300 values per second, i.e. more than three times faster. Interestingly, the more we tested, the higher the speed was - we will see how long this trend will continue :)
Conclusion
The threefold acceleration of data insertion into depositories is certainly worth using. It will allow us to reduce the time required to migrate depositories to the PostgreSQL platform as part of an ongoing and future project.
The modified arcsynchro will be available in the form of patches for version 11.0.53 and can be used for versions 9.1.31 and higher (since the structure of archive and vault databases has not changed since this version).
Ing. Peter Humaj, www.ipesoft.com
