
In previous blogs about archiving on the PostgreSQL database platform, I wrote about accelerating the Arcsynchro utility when populating PostgreSQL depositories (Arcsynchro and PostgreSQL depositories) and about migration results (Migrating depositories to PostgreSQL in practice) and optimizing writing to depositories (Archive and PostgreSql depository databases). In today's article, we'll take a look at the latest feature of the D2000 archive.
Depositories - what to do with them?
Depositories are the most disk-consuming item in most SCADA and MES applications. It is logical - the configuration database is usually small (tens to hundreds of megabytes), monitoring as well (maximum gigabytes, as it has a defined time depth). Archives can be large (in practice up to several terabytes), but again - thanks to the definition of the time depth of individual archive objects (usually months to years) they reach their "target" size over time and continue to grow only modestly, due to application expansion.
Well, not so the depositories. These databases are created by the D2000 Archive on a regular basis (with a configurable period) and are always only being added. In the past (on the Sybase SQL Anywhere platform) there was a trend to unmount and "move" depository databases (e.g. burn them to a CD and store them in a depository - from there they actually got their name). With the increase in available disk capacity and user requirements for the availability of historical data, the possibility of keeping depositories available (for reading) by the D2000 Archive has been added.
So today, the D2000 application manager finds himself between two stones. On the one hand, users want to have "all the data available", on the other hand, they have to fight with infrastructure managers (or the budget managers, if they manage the infrastructure themselves) for regular expansion of disk space.
Possibilities of the technology
Can the D2000 itself help the application manager in any way?
It turns out that the answer is yes. When using the Sybase SQL Anywhere database server, the depository was compressed by means of the Sybase SQL server after it was full. A compressed database (with a .cdb extension) was created from a database file (with a .db extension). Unfortunately, this feature has disappeared in later versions of SQL Anywhere (versions 11, 12). In addition, Sybase SQL Anywhere was not suitable for databases larger than a few tens of GB.
When we started deploying larger solutions built on Oracle databases, we basically didn't address the size of the depositories. Although Oracle offers features like Compression or Advanced Compression, we've never used them - since they were paid options, only available in the expensive Enterprise version.
Today, the preferred platform for D2000 technology is the PostgreSQL database - the most advanced open source database. We like it for easy administration, high stability, and good scalability.
One thing I personally missed about PostgreSQL is the absence of index-organized tables. It is a feature that both Oracle and Microsoft SQL Server have - the ability to store an index along with data in a single data structure. On the one hand, it speeds up work with data and on the other hand, it saves space. This feature helps save space in Oracle archives and depositories. In addition, the data format used by PostgreSQL contains a 23-byte row header. In summary, the archive size will be doubled after a conversion from Oracle to PostgreSQL.
What can we do about that? We usually enabled the compression of the directories in which the archive database was stored on the Windows platform. The compression ratio was about 2.2:1 and, according to our tests, had minimal effect on the speed and performance of PostgreSQL.
But in the case of depositories, we can do something even better.
Data compression in PostgreSQL
What does the DATA table, in which all the data in the depository are stored, look like? It contains the following columns:
- Id - numeric identifier of the object
- Row - a row number for structured archives
- Col – a column number for structured archives
- Time - timestamp
- Value - value
- Status, LimitStatus, ArchivStatus, Flags - various attributes of value
The values of Id, Row, and Col are identical for all values of a specific object (or for an item of the structured archive). Can we eliminate these duplications and reduce the size of the data?
The answer is yes. PostgreSQL supports columns of array type - such a column does not contain a single value, but an entire array (a vector). In addition, it allows you to define "structured types" - composed of simple ones. And by combining these two features we get a column in which we write an array of structures. And that's exactly what we need to reduce the size of depositories.
So what does the D2000 Archive do to optimize the structure of the depository database?
- It defines the user type d2trzitem, which consists of the items dTime, Value, Status, LimitStatus, ArchivStatus, Flags. The individual components correspond to the respective columns in the DATA table. The exception is dTime - more on that later.
- It creates a CDATA table with Id, Row, Col, Cas0, CValue columns. The last column is defined as an array of structures of d2trzitem type. All values of one archive object (or one item of a structured archive) will be in one row of the CDATA table.
- It performs the conversion itself – it populates the CDATA table with data from the DATA table and then purges the DATA table. This third step is the longest and most CPU and I/O intensive.
The attentive reader will notice that the CDATA table contains a column Cas0, not Cas. This is not a typo, but an intentional distinction between this column name and the Cas column in the DATA table. The Cas0 column contains the time of the middle of the interval for which the depository is created. Why the middle? Because we have introduced another optimization - the dTime item of the user type d2trzitem specifies the offset (in milliseconds) from Cas0. And since the standard PostgreSQL numeric types are signed, it's a good idea to define Cas0 as the middle of the depository time interval. If we have a depository covering less than 49.7 days (most of our customers use monthly, weekly, 2-week, or 10-day depositories), it is enough to define dTime as a 4-byte integer type (and save 4 bytes on each timestamp). Otherwise, the D2000 Archive defines dTime as an 8-byte bigint (and we save nothing compared to the 8-byte timestampdata type).
To optimize reading, depositories also contain the values of the objects they had when the depository was created. These values are older than the start time of the depository. Therefore, when the depository is compressed, these older values are moved to the DATA0 table, which has the same format as the original DATA table.
PostgreSQL and toasts
PostgreSQL implements a technique for storing "large" columns called TOAST (The Oversized-Attribute Storage Technique). The contents of large columns (in our case, the CValue column in the CDATA table) are transparently compressed and stored as blocks of constant size (2kB by default). This feature will further reduce the size of the depository.
When to compress?
The D2000 Archive can compress depositories automatically when full (if the TrezorCompress parameter is set to 1). Old depositories can also be compressed - this is what the TREZOR COMPRESS command is for. There is also a variant TREZOR DECOMPRESS command, which performs a reverse process - unpacking data from the CDATA table to the DATA table.
Compression can be performed in "test" mode - if the TrezorCompressKeep parameter is set to 1, the original DATA table is not purged. Subsequently, even in the case of large depositories, the TREZOR DECOMPRESS command can be used to return the depository to its original state in a few seconds.
What is compressed?
The tell command LIST_TREZORS has been extended to list the information that the depository is compressed (cps flag in the figure below).
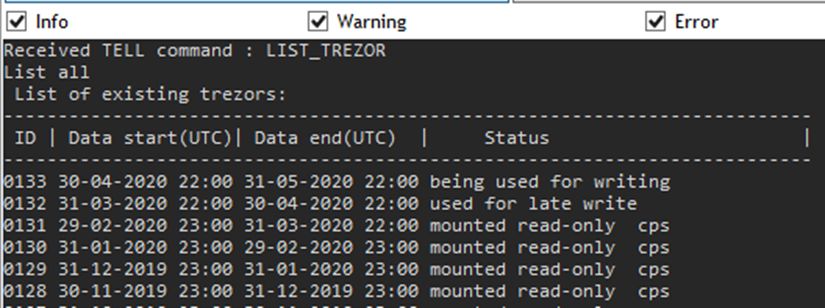
Limitations
Neither the D2000 Archive nor the D2000 Arcsynchro utility can modify compressed depositories. They can only read from them. Therefore, in case it would be necessary e.g. to add data to the compressed depositories, they must be decompressed first.
Even if we could modify the rows within the CDATA table, it would be too expensive - the writes would generate large REDO logs and old rows would remain on disk due to the "multiversion" architecture of PostgreSQL. So the compression is clearly in place after filling and closing the depository.
What are the limitations of PostgreSQL? There is a limit of 1GB for the size of any one field in the table. Therefore, if the depositories contain too many values for a single object, they will not be compressable. One option is to reduce the time period of depositories. The second is to reconfigure the problematic archive object (e.g. set on-change filters, or time filter for on-change calculated archives).
Are there any restrictions for users? Depository compression is performed in the background in addition to other activities of the D2000 Archive. When a particular depository is compressed, reading from it still works – data from the original uncompressed table are read. Therefore, users will not notice this activity at all - only reading may take longer when the disks are under the load of performed compression.
Speed
When deploying compression on production systems, we noticed that the duration of compression greatly depends on how "ordered" the data in the depository is. Therefore, another parameter TrezorCompressReorg was introduced, whose default value of 1 means that the D2000 Archive will perform a cleanup (reorganization - clustering of data in the DATA table by the index) before compression of the depository. The reorganization in the production system shortened the compression time of about 40 GB of the monthly depository from 24 hours to about 1.5 hours.
How is reading speed affected? The quick answer is that the average user doesn't notice anything. On the one hand, the time of reading data from the disk is shortened, on the other hand, the need to decompress the data is added. These two effects more or less cancel each other (although we have seen an acceleration at the millisecond level in a particular application). The reading may be slowed down in specific scenarios - if we need one or a few values from a specific time in the depository, then to obtain them, all values of the selected archive object must be read and decompressed. If you want to test working with compressed depositories, you can try compression in the "test" mode described above.
Results and benefits
This parameter will probably be the most interesting for administrators of D2000 depositories. So how much have the depository databases shrunk after compression? A quarter? Or up to half?
After the implementation of depository compression and testing on "synthetic" data, we measured a 10-fold reduction in the size of depositories, but we took these numbers with a grain of salt. Anyway, we were curious about the results, so we added the messages about the sizes of DATA table before the compression and CDATA table after the compression to the D2000 Archive (using the PostgreSQL function pg_total_relation_size, which returns the size of the table including indexes and TOAST data).
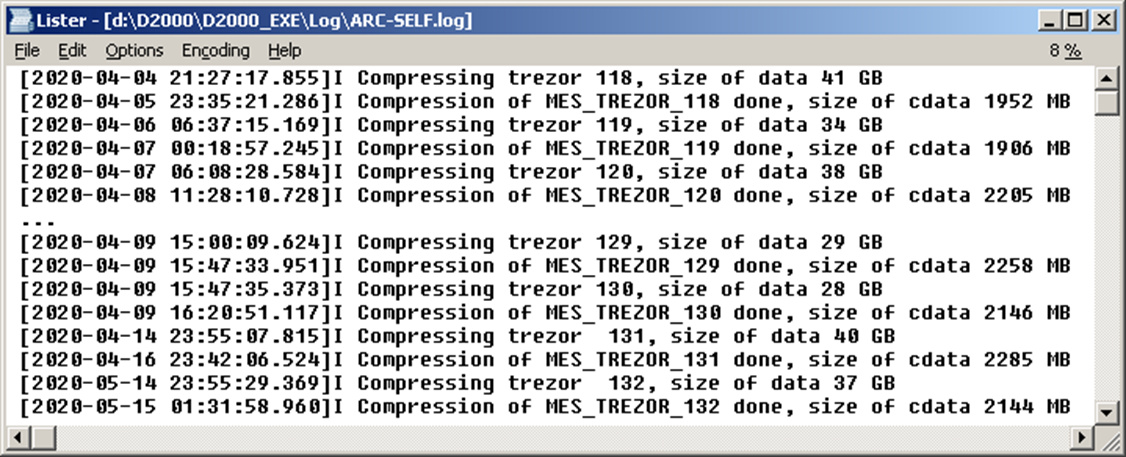
The compression reduced the size of some depositories 12-times, others 15 or 17-times. For some depositories, the size has been reduced by up to 20-times, but it is possible that the data in these depositories have been "fragmented" and not properly reorganized.
In the previous figure, it can be seen that the compression of the depository 131 took almost 24 hours, but the compression of the depository 132 took only about 1.5 hours - between these two compressions, the already mentioned cleaning of the depository prior to compression was implemented.
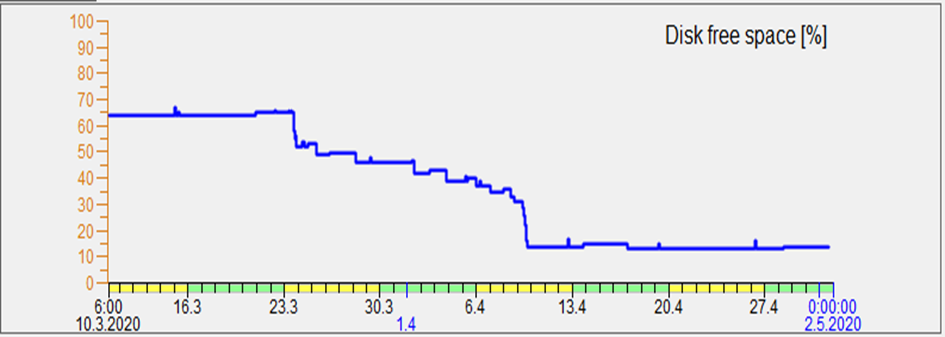
The next figure shows the occupancy of space on a 460 GB disk with depositories. As a result of compression (March 23 to April 9), the occupied space was reduced from about 65% (300 GB) to 60 GB. With 2.5 GB of compressed depository data per month, free space is enough for more than 12 years. Without compression (at 30 GB of depository data per month), the drive would only last for 1 year. This is a concrete and tangible benefit for the D2000 administrator, or for the disk array administrator.
Conclusion
Depository compression on the PostgreSQL platform is one of the interesting features that the new version of the Ipesoft D2000 real-time application server brings to both existing and new users. I believe that compression will be used by many of our customers and OEM partners, and I look forward to their feedback.
