
This is a third blog of a series dedicated to topic of archiving on the PostgreSQL platform. In past blogs, I wrote about accelerating the Arcsynchro utility while loading PostgreSQL depositories (Arcsynchro and PostgreSQL depository databases) and about results of migration (Depository databases migration to PostgreSQL in practice). Today's article is related to several months of experience with the operation of a large archive and depositories on the PostgreSQL platform.
Application
So – how big depository databases are we talking about? The application for a particular client has depository segments turned on (segments 0-4, i.e. five depository databases with a one month period are created). The figure below shows the size of individual databases as well as the total size of 135 GB of depository data.

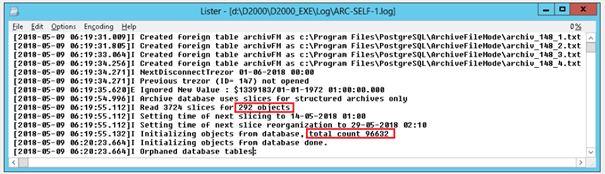
The application configuration contains approximately 59,000 archive objects. Of these, 292 are structured, so the total number of archive objects including structured archive items is more than 96,000.
Every second, between 700 and 1200 values are added to the archive database. Most of archive objects are also in depository. Assuming 50 bytes to store one value and average 1000 values per second, the size of the 30-day depository database is 50 bytes/value * 1000 values/second * 86,400 seconds/day * 30 days = 129.6 GB which roughly corresponds to the size of the April depositories (135GB).

The archive load of approximately 1000 values per second is typical for large SCADA applications. With the optimized use of a combination of memory operations (application cache of archive in mode of isochronous cache) and database operations in D2000 Archive, the D2000 is capable of handling a few thousand inserts per second in the high-performance (enterprise) server & storage environment without noticeable slowdown of read operations that have higher priority (fast response of graphs).
Problems
During the archive operation, it happened several times that the given data stream (about 1000 values per second) written into five depository segments was not always attainable. In part, it was caused by depositories being located on a relatively low-performance NAS data storage RS2416RP +, partially it was caused by PostgreSQL periodic maintenance operations (vacuuming), in part by non-optimized batch write in the PostgreSQL ODBC driver.
The result was a gradual increase in memory consumed by the archive to buffer unsaved values and subsequent crash of archive.
Solution
Moving depositories to a faster disk storage (or using SSD technology) would definitely help. But can we get more power from the existing hardware configuration? It turns out that the answer is yes.
We used the same solution as in the case of the acceleration of depositories being loaded by arcsynchro utility described in the Arcsynchro and PostgreSQL depository databases blog. Because the principle is the same, the limitations and implementation requirements are also the same - the archive must run on the same server as the PostgreSQL database, respectively there must be a common file path accessible to both the archive and the database.
A new parameter PG_TrezorFilePath was added to archive parameters. It specifies a directory in which the archive will create files with values to be written to the depository. The directory must be writable for the archive (by default running under the SYSTEM user) as well as for the PostgreSQL database server (by default running under the NETWORK SERVICE user). The files will be named archiv_ <TrezorId> _ <SegmentId> .txt (e.g. archiv_4_1.txt).
If the PG_TrezorFilePath parameter is set, instead of inserting values through the ODBC interface (as parameters for batch INSERT or UPSERT commands), the archive will store the values into files for the appropriate depository segments. If a sufficient number of values are inserted into a file or a period (specified by the CommitTime configuration parameter) has elapsed, the archive performs the insertion of values (UPSERT) from a remote table represented by the appropriate file on the disk (using the UPSERT command means that PostgreSQL 9.5 and higher is required).
But what does "sufficient number of values " mean? When inserting values into archive or depository databases, COMMIT is performed by default when CommitCount values are inserted (default value is 1000), respectively after the CommitTime period (the default is 60 seconds). In case of inserting values from remote arcsynchro tables, it was demonstrated that inserts can be also performed with much larger batches (e.g. 100,000 values). Therefore, another parameter PG_TrezorFileMulti was added, preset to a relatively conservative value of 10, which defines a multiplier for insertion into a depository. The archive will execute the UPSERT to insert data from the remote table into the depository if CommitCount* PG_TrezorFileMulti values (i.e. 10,000 by default) are accumulated in the remote table.
At the same time, the tell command SET_OPTION was enhanced to allow the value of parameter PG_TrezorFileMulti to be set during the archive run, and the tell command SHOW_CONFIG was enhanced to display the values of new configuration parameters of the archive.
Tuning
When implementing the insertion of values from remote tables, we stumbled upon one property of UPSERT that did not show up when using arcsynchro utility. If UPSERT is executed on multiple rows that contain duplicates (having the same primary key), the operation fails. In the case of arcsynchro, this was not possible since the data was read from the source table where the same key was defined as in the target table. In the case of the archive, however, the calculated or statistical archive values are often „corrected“ after arrival of the delayed value.
What can we do about that? A solution is relatively simple - instead of immediately inserting values into a file, they are temporarily stored in the binary tree in memory. It is based on the same key (ID, ROW, COLUMN, TIME) as a table in the database. Therefore, if a new value with the same key arrives, it replaces the previous one, and duplicity can not occur. If there is more than CommitCount * PG_TrezorFileMulti values in the tree, they are written into a file and UPSERT is performed.
As instead of performing an insert of a value and then an update, only the insertion of a newer value is performed (if both values are inserted in a single batch), the database load will be reduced– less WAL data will be generated (write ahead log, analogy to REDO Oracle logs) and less data will be inserted into data tables. Less data in tables is related to the fact that PostgreSQL implements the so-called MVCC model (Multiversion concurrency control), which means that there is a row with the originally inserted value as well as a row with a changed value, until regular cleaning – called vacuuming - removes outdated values that are no longer needed by any of the running transactions.
Conclusion
After testing under laboratory conditions, the modified archive runs for weeks in production. During this time, there was no increase in the memory of the archive caused by the failure to write into depositories - although for several days reorganization of data was performed in older depositories.
At the same time, there was a decrease in I/O operations on the disk drive with depositories and in the percentage of time during which the disk is active – these indicators are detected using the Resource Monitor software that is a part of the installation of Windows Server 2008 R2 or 2012.
Optimization of writing into PostgreSQL depositories using external tabels is another of the modifications that help increase the performance of the D2000 archive subsystem and push further the limits of PostgreSQL's database capabilities as a storage for archive and depository data suitable for the most large-scale MES applications currently built on D2000 technology.
The message for our customers – whether small or large ones - is clear: the combination of the D2000 Archive and the PostgreSQL database server is today powerful enough for the vast majority of applications - even when using a standard hardware.
