
In the previous blog "Arcsynchro and PostgreSQL depository databases", I wrote about the ways in which we managed to speed up the work of the arcsynchro tool in filling depositories in the PostgreSQL database. At the same time, I wrote that this acceleration took place within the project of conversion of depository databases of a specific customer. Today, the migration phase of old depositories is successfully completed - let's look at how it went and how long it lasted.
First of all, I would like to state that this was one of the biggest (if not the biggest) migration of depository databases from Oracle to PostgreSQL that we did or we ever will do. Why? For the simple reason that this MES system was put into production in 2004 and the depositories were enabled at the beginning of 2006. There are currently 146 monthly depositories. In addition, depository segments are also active in this application, so 5 segments (0-4) are created every month.
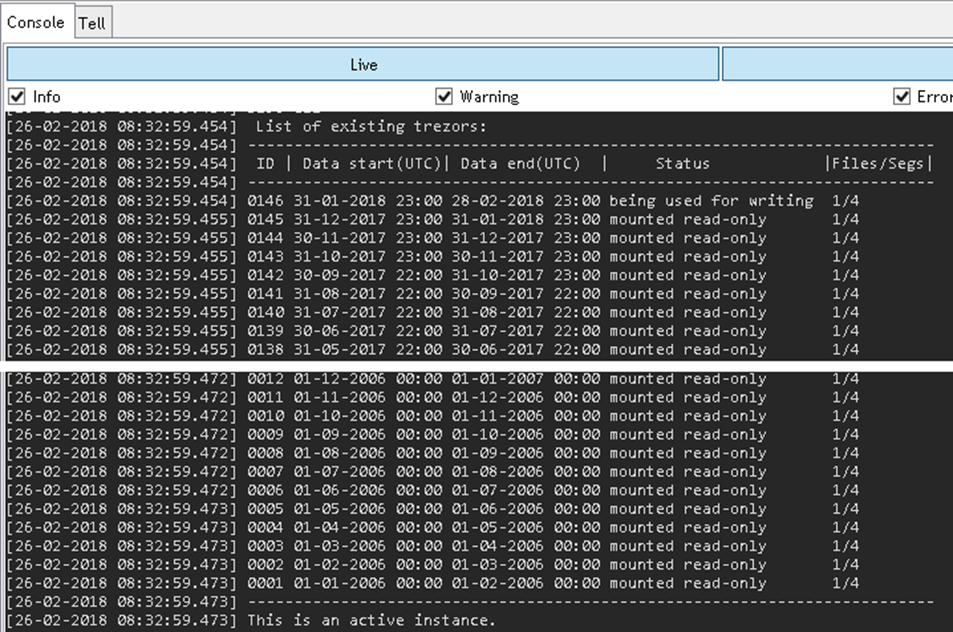
The size of depositories has gradually increased due to the development and expansion of the MES system - the depository segments from January 2018 on the Oracle platform are already over 70 GB.
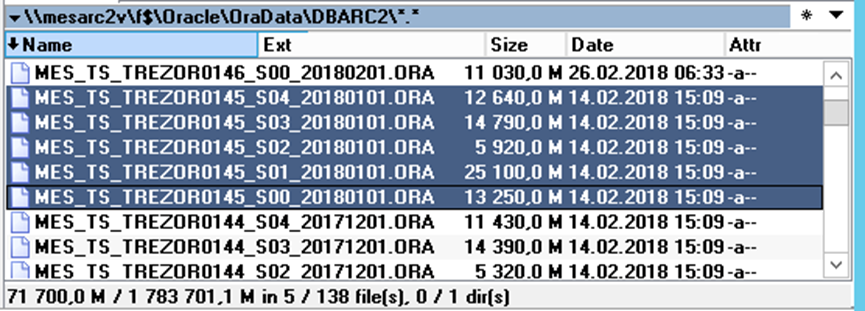
Interestingly, the archive contains a configuration of more than 58,000 archive objects, many of which are structured archives - as a result, more than 96,000 startup values are read from the database when the archive is started.
So how did the migration to PostgreSQL go?
The first phase was the migration of the archive database. An archive was run over the empty archive database, which created tables in the database and started filling it with data. Subsequently, data from the Oracle archive were migrated to the archive using the arcsynchro utility. The migration took place between October 6, 2017, and October 29, 2017.
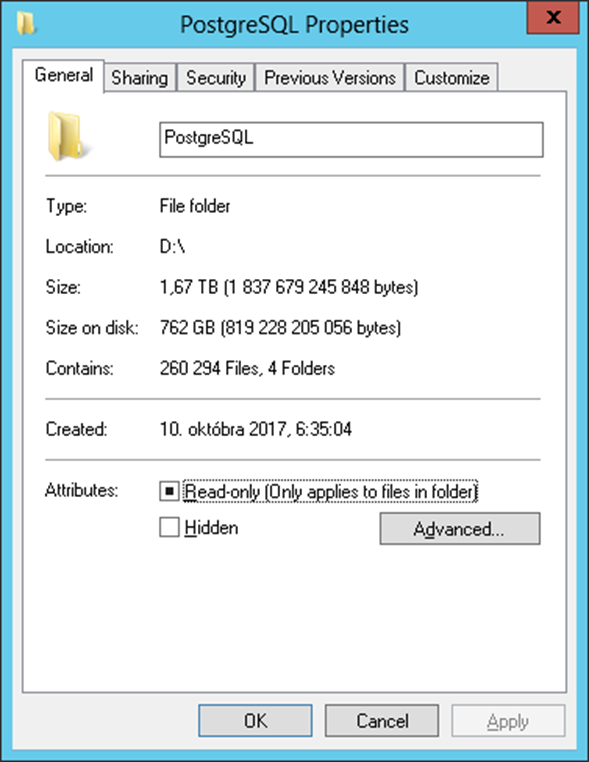
Subsequently, we created a separate PostgreSQL database for each depository segment and initialized its structure with a script. Subsequently, it was necessary to run arcsynchro for each depository segment to migrate data from Oracle to PostgreSQL.
The migration started on October 31, 2017, and ran from the newest depository to the oldest. At the end of November (24.11), the “file mode” was used for the first time during the migration, which accelerated the migration more than three times by using external tables (foreign tables) represented by files on disk. The filling phase lasted until February 25, 2018, i. almost 3 months.
During this time, we gradually created more and more depository databases. In addition, it was necessary to solve problems with the number of connections to these databases - the archive kept one open connection to each depository database (for reading data), which consumed system resources (memory, handle) on the PostgreSQL server-side. Therefore, the read functionality for PostgreSQL depositories has been modified so that connections open and close dynamically while reading - the advantage is, in addition to saving system resources, that reading a specific depository by multiple tasks is no longer serialized due to using one common database connection, but each task opens its own connection.
Interestingly, the disk for depository databases is located on the NAS data storage RS2416RP+ (rack version, equipped with 12 disks with a usable capacity of about 30 TB), which is connected to the archive server as an iSCSI device via Gigabit Ethernet - so basically simple and relatively cheap solution (cheap compared to powerful disk arrays).
What next? "Cleaning" is currently underway - all depository data tables are reorganized to speed up reading - via the SQL command "ALTER TABLE CLUSTER ON INDEX" so that the data structure copies the index of the table and so the reading is faster.
Subsequently, the program will create a backup of depository databases on an independent disk array, in case of damage or accident (similar to the backups created for Oracle depositories). Finally, the archive will be tested for several months as an active instance that provides data to users.
Conclusion
For several years now, PostgreSQL has proven its usefulness and stability as a repository for archive and depository data of systems based on the D2000 real-time application platform. The migration of more than 12 TB of depository data covering a period of 12 years proves that this database platform is applicable in practice not only to small and medium-sized solutions but also to the largest ones that our customers currently operate.
February 26, 2018, Ing. Peter Humaj, www.ipesoft.com
