
On the 21st of June 2018, there was a workshop about archiving in the D2000 system on the premises of the IPESOFT Company. What important has been said?
In the beginning, B. Čonto, the head of the development, welcomed the participants. The topic of archiving was apparently attractive for our partners and customers, as the workshop had a high turnout – our big conference room was filled to capacity.
After a few introductory words about the archive and archiving, we discussed the basic archive functionality – with what types of values does the archive work and what does it archive? Then there was a section about supported types of SQL databases. Judging by the feedback, it was interesting for the majority (maybe also because of the ongoing upgrades and because of the need to switch between database platforms).
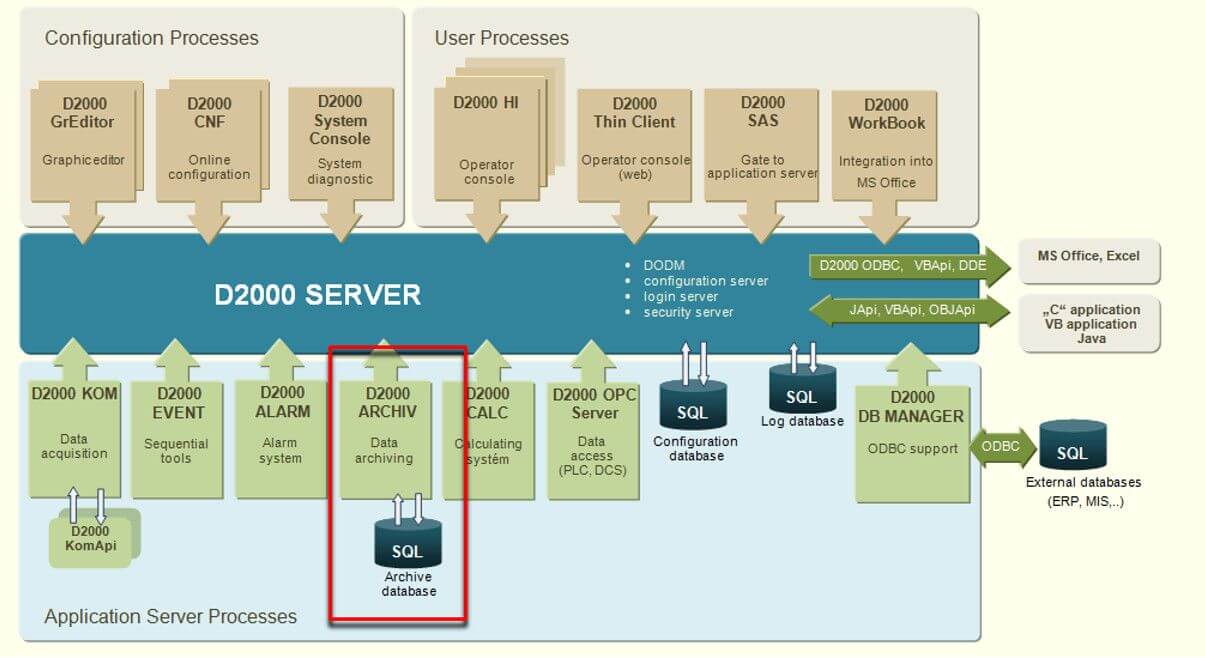
After that, we went through types of archiving objects that exist in the D2000 system. We said a few interesting facts about the basic archives (primary and statistical archives) – e.g. that data for statistical archive can be from different time interval than its archiving period). Then, we moved to calculated and script-filled archives. This topic was also new for many participants. For instance, new information was that calculated archives have functions such as %Arc_GetValue or an invariable @EvalTime setting the time for which the calculation occurs. Another news was that the calculation can end with %Arc_NoWrite function that will cause for the calculated value not to be written into the archive, or else %Arc_UnWrite function that even erases the value during calculation if it already exists in the archive database.
From types of archives, we continued to the fact that whole archive ‘trees’ of mutually dependent archive objects can be constructed. Fluently, we moved on to the consistency of archives and to the condition of a calculation. Did you know that for example arrival of old values from communication can cause (depending on the configuration of the calculation condition) automatic recalculation of all dependent calculated and statistical archives, so the values in the archive are consistent?
After a break, we focused on the existence of structured archives which simplify, speed up, and make the configuration of big applications with repetitive technologies clearer. For instance, if we have 50 identical manufacturing machines, after organizing them into structured variables, we can visualize them by one instance scheme and archive them effectively by structured archives.
Another discussed topic was creating depositories – long-term data archiving. We explained the basic principles and ways to implement depositories on Sybase, Oracle and PostgreSQL platforms.
Part of the lecture was also the D2000 Archive and redundancy. We talked about redundant archives (two instances are used standardly, or else three in HADR systems) and described the optimal way of configuration if the application server is also redundant.
If we already have two or more archives, it is necessary to handle their synchronization and patching their holes – arcsynchroutility helps with that. We talked about its individual modes of functioning (automatic and manual).
Those interested in performance improvements of archives could learn more in following parts of the workshop. Features such as load-balancing of more D2000 Archives, parallelizing with the use of multi-write and multi-read archives, time slices, archive cache, and optimization of recalculation of intervals enable to effectively use RAM and CPU capacity available in present servers with the aim of archiving and providing the data in the fastest way possible. We also mentioned performance optimizations for the PostgreSQLplatform.
The section ‘Debugging and diagnostics’ introduced a range of possibilities which the D2000 Archive offers in various performance analyses, diagnostic interventions and in statistical data acquisition of the most burdened archive objects.
A bonus was a section about a historical mode of schemes. Did you know that any SCADA scheme can be easily switched into historical mode using the button with %History function and subsequently it is possible to go through values (by individual changes or by specified time steps) which the scheme displayed in a certain time in the past? Understandably, object values in the scheme must be archived so the HI process could have historical data.
In the section Questions and answers, besides archive questions, we ‘enticed’ participants to some attributes of the upcoming D2000 version 12. We also mentioned a plan for the forthcoming D2000 training:
| Name of the training | Duration | Date | |
|---|---|---|---|
| High-performance archiving | 2 days | 10.-11.7.2018 | |
| Event script language | 2 days | 22.-23.8.2018 | |
| Java Application Interface (JAPI) | 2 days | 26.-27.9.2018 | |
