
This is the second blog in a series of reflections on several aspects of SCADA systems. All are based on the experience of mine or my colleagues. I believe that the lessons learned can be useful for others - implementers as well as users of SCADA systems.
This blog will deal with the influence of database technologies (and possibly their prices) on the overall design of SCADA systems.
Story
This time I will not start with my own story, but somebody else‘s. An interesting presentation originally available on the CERN website describes how CERN (the European Organization for Nuclear Research) was able to use the WinCC Open Architecture (WinCC OA) archive subsystem to archive more than two hundred thousand values per second into an Oracle database.
An impressive number at first glance.
As I was interested, I was looking for more details than the presentation offered. I found them in the published article Database Archiving System for Supervision Systems at CERN: a Successful Upgrade Story (link to PDF document) by P. Golonka, M. Gonzalez-Berges, J. Hofer, A. Voitier.
In the beginning, they write about an upgrade that migrated 200 control applications at CERN from file-oriented archiving to a centralized infrastructure based on Oracle databases.
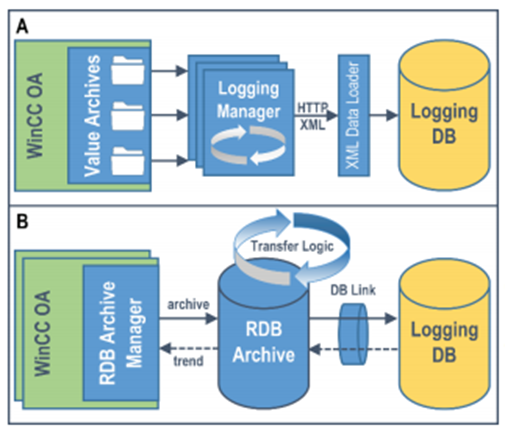
The original method of archiving (Figure 1, part A) was to import XML data into the archive database "Logging DB". The authors write about the complicated configuration of up to 10 WinCC OA archive manager processes on each of the control systems.
The new method (Figure 1, part B) means that the RDB Archive Manager process in each of the control systems writes to a centralized Oracle database (RDB Archive). Long-term data is copied to another Oracle database (Logging DB), so the data in the primary RDB Archive database has a limited time depth (typically 3 months according to the article).
Subsequently, the authors describe the testing phase, when 50 servers running 200 WinCC OA applications stored data in a centralized RDB Archive database (a 2-node Oracle RAC cluster was used). There were problems with the I/O throughput of the subsystem - although it was able to perform the required writes, the readout was bad due to an I/O bottleneck. The architecture indicates that readouts were needed to move the data to a long-term archive - Logging DB, to which they needed to copy most of the data within 15 minutes. The authors describe the use of IOT (index-organized tables), which reduced the size of tables and accelerated I/O operations. But that was not enough. Another bottleneck was the number of generated REDO logs when inserting data. This was directly related to the row size (59 bytes in the RDB Archive database, but only 19 bytes in the Logging DB). The authors further write about how they optimized the structure of tables (metadata reduction, time partitioning). Subsequently, they tested the solution - together with a simulation of an 8-hour outage, during which the control systems stored data on disk and then within 2 hours after the outage they were able to write stored data to the database, at a rate of 1 million values per second (200 thousand were new data being inserted, 800 thousand were data from files).
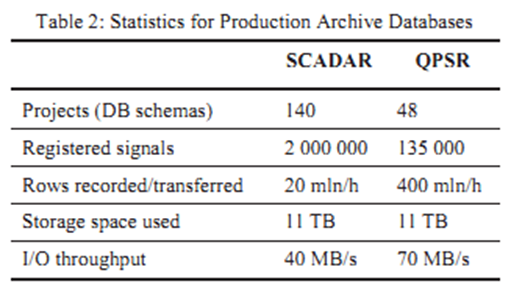
Furthermore, the authors describe the deployment in production. They used 2 databases (each on a 2-node RAC cluster) - one (called QPSR) dedicated to 48 demanding (in terms of data and reliability requirements) QPS applications, the other (called SCADAR) for the remaining 140 applications. They wrote that working with 200 schemas (creating and deleting objects) would have been difficult without an automatic tool.
Analysis
As I read this article and began to "digest" it, I wondered: Why try to store all the data of 200 applications in a single database? A scenario in which each application has its own archive database (or even several redundant ones) seems much more practical to me. The old lesson is that the price does not increase linearly with performance (and it doesn't matter if we are dealing with CPU performance or disk I/O throughput). In the case of the CPU, this was respected (the authors mention 50 servers with 200 applications and do not talk about migrating to one "super server"). Why did they not follow this principle in the case of archive databases?
One answer may be that they wanted to have data "in one place" - to manage the database schemas they mention, to deal with disk space, and so on. From the point of view of the developer of the Ipesoft D2000 application server, I can say that these reasons are irrelevant in our system. The D2000 Archive automatically creates tables as needed and does all the necessary maintenance of the database (including any "cleaning" of tables after periodic deletion of data). As far as disk space is concerned, the archive usually grows until the configured archiving depth is reached and then its size practically does not change. Anyway, we service and monitor more than a hundred archive databases of our customers, and in the event of a decrease in free disk space below the configured limit, we begin to address its increase (or analyze the cause for disk usage growth). By the way, the D2000 Archive by default guards free disk space on the disk with the database and generates system alarms if it has dropped below 10% of the size of the archive database.
So I have another answer: the architecture of the solution is directly affected by Oracle's licensing policy and the cost of running Oracle databases.
"Data partitioning" is mentioned several times in the article. Oracle experts know that partitioning technology is only available in the Enterprise version of Oracle (Standard and Standard Edition One as well as Standard Edition 2, which was created in 2015 and replaced the previous two, do not permit it).
The Enterprise version of Oracle is rather expensive and its price is derived from the number of named users (NUP licenses) or from the number of processors (more precisely, processor cores). Just to give you an idea: the price list states $ 47,500 per CPU while defining a factor of 0.5 for x64 multi-core server processors. Thus, a license for a server with a 16-core processor costs 47,500 * 16 * 0.5 = $ 380,000 and the annual maintenance fee is 22%. Here you can see why e.g. D2000 Archive does not use Oracle partitioning. Utilizing this otherwise useful feature would be too expensive for our customers, as it would require the purchase of an Oracle Enterprise license and, in addition, a separate license for the Partitioning feature ($ 11,500 per CPU, that is an additional $ 92,000 for the abovementioned 16-core server).
Note: Our solution to this problem was to implement our own "custom" partitioning, which we named time slices. The advantages are one-time development costs and usability on all database platforms supported by the D2000 Archive.
Licensing Oracle in virtualized environments is even more complicated, and I admit I don't understand it. However, I understand that if each of the 200 control applications were to have their own archive database built on Oracle, it would not be financially viable for CERN either.
How would we solve a similar problem in D2000?
Each of the 200 applications would have its own archive (since this is important data, the archives would be redundant, i.e. two D2000 Archive processes, each writing to its own archive database). We would use PostgreSQL as the archive database. Today we already have applications with archives with a size of more than 2 TB of data (plus depositories for about 15 years with a size of 13 TB). Today's commercial servers for several thousand euros equipped with local disks can write tens of thousands of values per second.
If we needed to "centralize" data from multiple applications in one place, we would create one "parent" application to which the others would be connected using the D2000 Gateway process. The only improvement that would need to be implemented to avoid local archiving is to support reading archive values from a remote system via the D2000 Gateway (in fact, this functionality already exists in part, but only in the form of reading data with the GETOLDVAL command).
Don't get me wrong - I recognize that Oracle is currently the most advanced commercial database. It is also a fact that thanks to IOT tables, the archive on Oracle is 2 times smaller and according to our tests about 25% faster than on PostgreSQL. Several corporate customers use the D2000 Archive on the Oracle platform.
On the other hand - D2000 Archive does not use 99% of advanced Oracle features (archiving functionality is trivial from the point of view of SQL database - that is why D2000 Archive can work even with SQLite database). And it's much more efficient for our customers to make a one-time investment in larger and faster disks and powerful multi-core processors to get the performance of the archive subsystem to the required level with „brute force“ than to buy an expensive Oracle license (and pay annual maintenance fees to for support and patches).
In addition, our more than 6 years of experience with PostgreSQL shows that this database works very reliably, stably, and is practically maintenance-free, so the total cost of the PostgreSQL archive is low.
In practice, we also had to deal with similar issues with Oracle licensing. For example, customers with an otherwise completely virtualized environment use physical servers for Oracle databases - due to the complications and cost implications of licensing in such an environment.
Conclusion
An analysis of the implemented architecture of shared archive databases for 2000 control applications at CERN in Switzerland shows a significant impact of the Oracle database price on the overall design. In my opinion, both direct costs (the cost of the Oracle database and its maintenance) and indirect costs (the cost of database administration) have led to the implementation of a sub-optimal centralized solution. Distributed architecture using a larger number of independent redundant archives seems more appropriate to me.
I do not question a technological sophistication of the Oracle database, but the rationality of its use in a particular case. It is more advantageous for the customers if the supplier of the SCADA solution can offer them a choice of several database technologies and take into account their specific requirements. And last but not least, it's more convenient for the vendor - it increases his competitiveness and he doesn't have to pass on the price of databases to the customer.
September 25, 2020, Ing. Peter Humaj, www.ipesoft.com
Addendum – September 2023
A few days ago, the so-called historical mode of the D2000 Gateway Client has been implemented (a blog). This mode allows the D2000 Gateway Client to pretend to be an archive process that mediates reading from remote historical objects. The master application would have 200 such "as if" archive processes, using which it would access 200 SCADA applications with source historical data. Similar to the so-called transparent mode, also in this historical mode the D2000 Gateway Client functions as a data diode, i.e. it allows data transfer only in one direction and does not support writing to source historical objects.
