
This is the first in a series of blogs about the architecture of SCADA systems. In them I would like to address the important features of SCADA technologies, the presence (or absence) of which affects the functionality, user-friendliness, usability and scalability of these technologies. This blog will be about a feature we call referential integrity in the Ipesoft D2000 real-time application server.
What is referential integrity?
References are the relationships between D2000 objects - if one object uses/needs another. If, for example, the measured point is displayed on the scheme, the scheme "needs" it to function. The measured point in question will therefore be included in the scheme references.
References can be of two types:
- Static – usage is part of the configuration - see example above. This binding is permanent and can only be canceled by changing the configuration.
- Dynamic – the object is used dynamically – for example, the user opened the diagram in the D2000 HI graphical interface, or opened the list of objects in the D2000 CNF configuration tool. This binding is dynamic, short-term and disappears e.g. by closing the schema or closing the object list.
We call referential integrity the assurance of checking that the configuration of the SCADA application is consistent at every moment - i.e. all used objects exist and an object that is used in the configuration of another object cannot be deleted.
Also during mass configuration changes (XML Import), the consistency of the application is checked - XML import is not performed if the imported objects contain references to other objects that are not in the existing application or among the imported ones.
Referential integrity is guarded by the core of the D2000 system – the D2000 Server process, which maintains the entire application configuration – primarily in the operating memory and subsequently synchronizes configuration changes to the configuration SQL database.
Referential integrity was part of the D2000 system design from the beginning - it was required by the designed DODM (dynamic object data model), which was supposed to be dynamic (configuration changes at runtime) and object-oriented (configuration exists in the form of objects and relationships between them) and therefore had to ensure configuration consistency.
What is it good for?
In addition to maintaining application consistency, referential integrity is an invaluable aid in building and maintaining large-scale SCADA systems. It allows you to trace data flows and application logic by tracing the relationships between objects.
I will show it in the simplest way with an example:
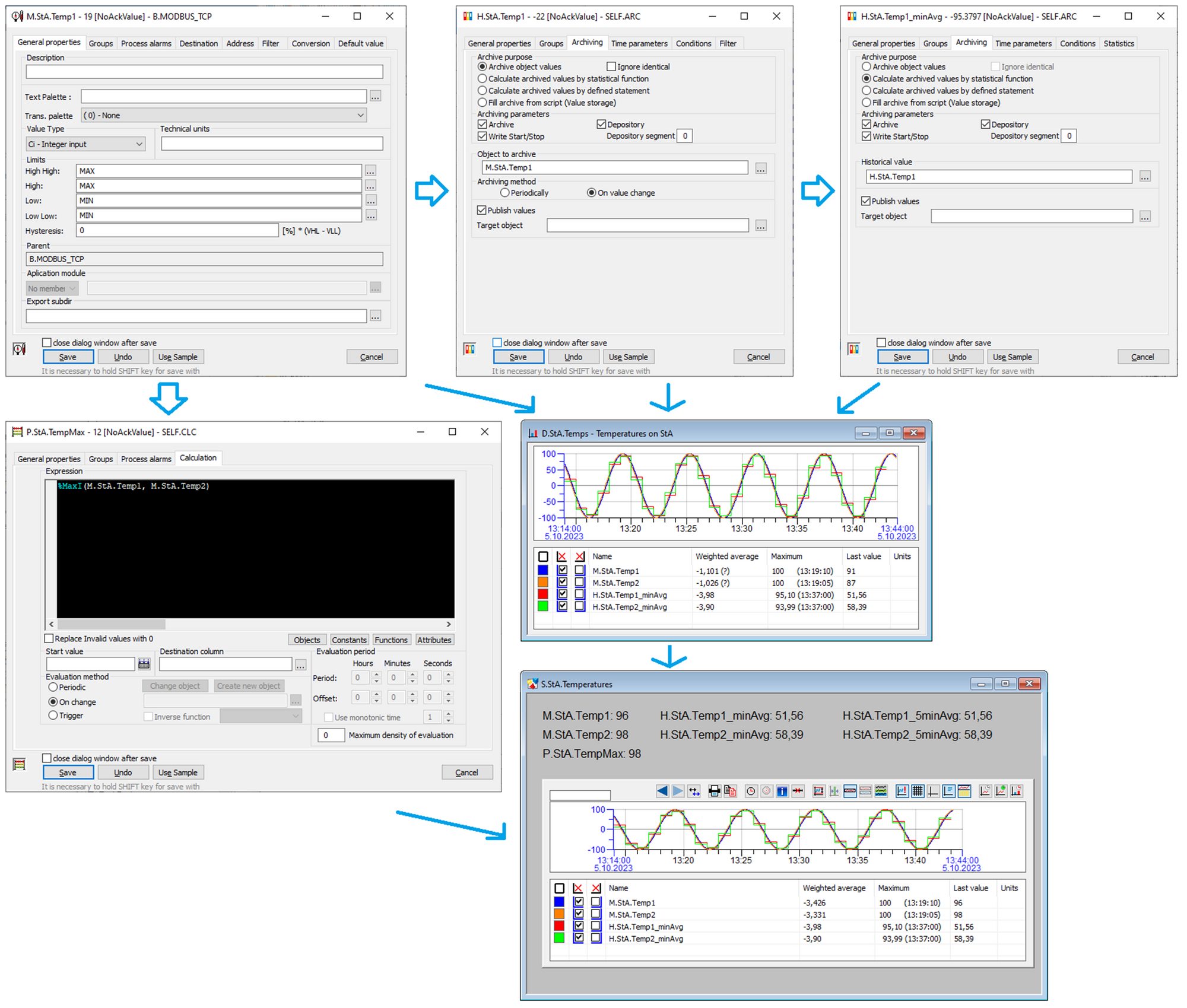
In the application, there are the measured points M.StA.Temp1 and M.StA.Temp2, which measure the temperatures of the StA station. These are archived by archive objects H.StA.Temp1 and H.StA.Temp2. Subsequently, statistical archives H.StA.Temp1_minAvg and H.StA.Temp2_minAvg are configured, which store their one-minute weighted averages, and other statistical archives H.StA.Temp1_5minAvg and H.StA.Temp2_5minAvg, which store 5-minute weighted averages calculated from minute ones.
In addition, there is a calculated point P.StA.TempMax that calculates the maximum of the temperatures M.StA.Temp1 and M.StA.Temp2.
All mentioned objects are visualized on the scheme S.StA.Temperature, while the measured points and archive objects are also displayed in the graph D.StA.Temps, which is also part of the scheme.
The following figure shows the configuration of the mentioned objects in the D2000 CNF tool or their visualisation in the D2000 HI (graph and diagram).
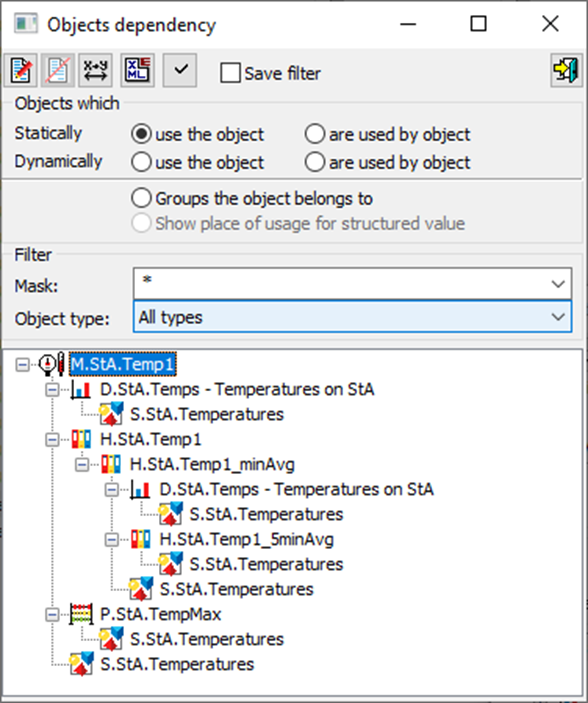
Using the dependency display, it is possible to find out who statically uses the M.StA.Temp1 measured point and the objects dependent on it:
In Figure 2 all the dependencies described above can be seen. In the case of a large number of dependent objects, it is possible to filter by object name and type.
In this way, it is possible to follow the flow of data from the measured point, through the calculated points, archive objects and other types of objects, to the possible display on schemes.
One object can be found in the tree more than once if it uses several objects dependent on the measured point - e.g. the S.StA.Temperatures scheme uses (displays) all other objects - measured point, archive objects, graph and calculated point.
This same dialog also allows viewing in the opposite direction - ie. it is possible to find out which objects are used by another object. If we start with a schema and figure out which objects it uses/needs, we get an object tree like this:
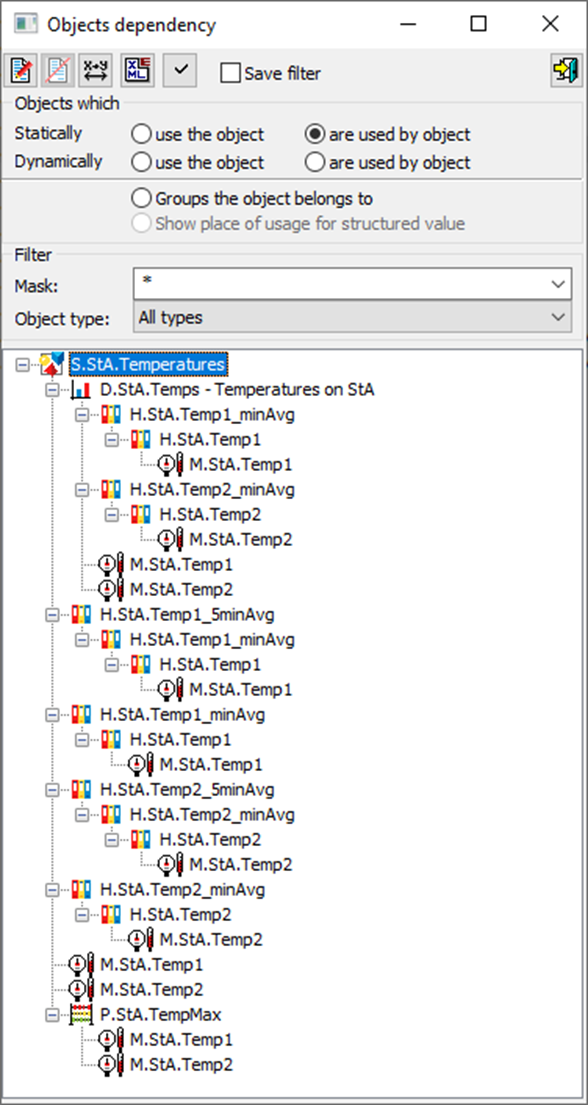
The dialog also allows displaying dynamic dependencies:
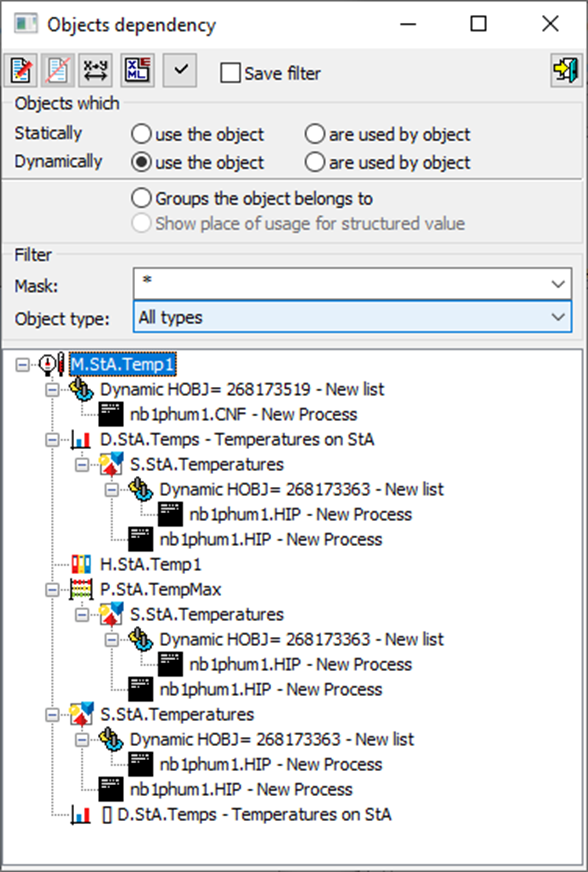
We can see that the measured point is open in the dynamic list in the CNF configuration tool (process nb1phum1.CNF). The S.StA.Temperatures scheme is open in the HI graphical interface (nb1phum1.HIP process) as well as in the object list (also in the nb1phum1.HIP process).
Dynamic dependencies will also help capture the use of D2000 objects by external programs - e.g. opening the object through the D2000 OBJApi interface intended for C/C++ programs or D2000 VBApi from the Microsoft Visual Basic / Microsoft Excel environment.
Performance
Tracking dynamic dependencies between objects enables the implementation of an optimal "push" architecture. The D2000 Server process knows which process uses which objects and therefore needs their values. For example, after opening a scheme in the graphical interface, HI starts sending it changes in the values of all objects that the scheme needs. When the schema is closed, sending values stops. In this way, it is ensured that the D2000 Server is not overwhelmed by periodic polling about value changes. By the way, I was dealing with a SCADA system that had all the objects and their values in an in-memory SQL database, and its user interface process periodically (every 2 seconds) queried this database. Not only did it put a load on the server, but it was not able to display rapid changes in values (several times per second). The D2000 architecture does not suffer from such shortcomings thanks to the monitoring of dynamic dependencies.
One more note: to implement a "push" architecture, it is enough to know the dynamic dependencies of objects. Therefore, there can be SCADA systems in which client processes tell the server that they are interested in specific tags, and then the server sends them the values of those tags - without implementing referential integrity. So if a measurement point used in a schema is deleted, when the schema is opened and the value of the measurement point is requested, the server reports "object not found".
Does your SCADA system also have referential integrity?
The quick answer is: probably not - I don't know of a competing system that implements it (please let me know if I'm wrong). This is a unique and very useful feature, but it must be incorporated into the basics of the system architecture. For example, if you use text object identifiers (e.g. Ignition or WinCC OA SCADA systems), I can't imagine implementing referential integrity.
Conclusion
Referential integrity in the Ipesoft D2000 real-time application server is a great system feature that ensures configuration consistency, prevents the object in use from being deleted, allows you to track the flow of data and application logic according to the links between individual objects, and distribute object values to processes that need them. Without referential integrity, the creation, servicing and further development of large-scale SCADA and MES systems would be much more demanding and complicated - so let's be grateful to the creators who incorporated referential integrity into the very design of the Ipesoft D2000 system!
October 23, 2023, Ing. Peter Humaj, www.ipesoft.com
